
媲美OpenAI事实性基准,这个中文评测集让o1-preview刚刚及格
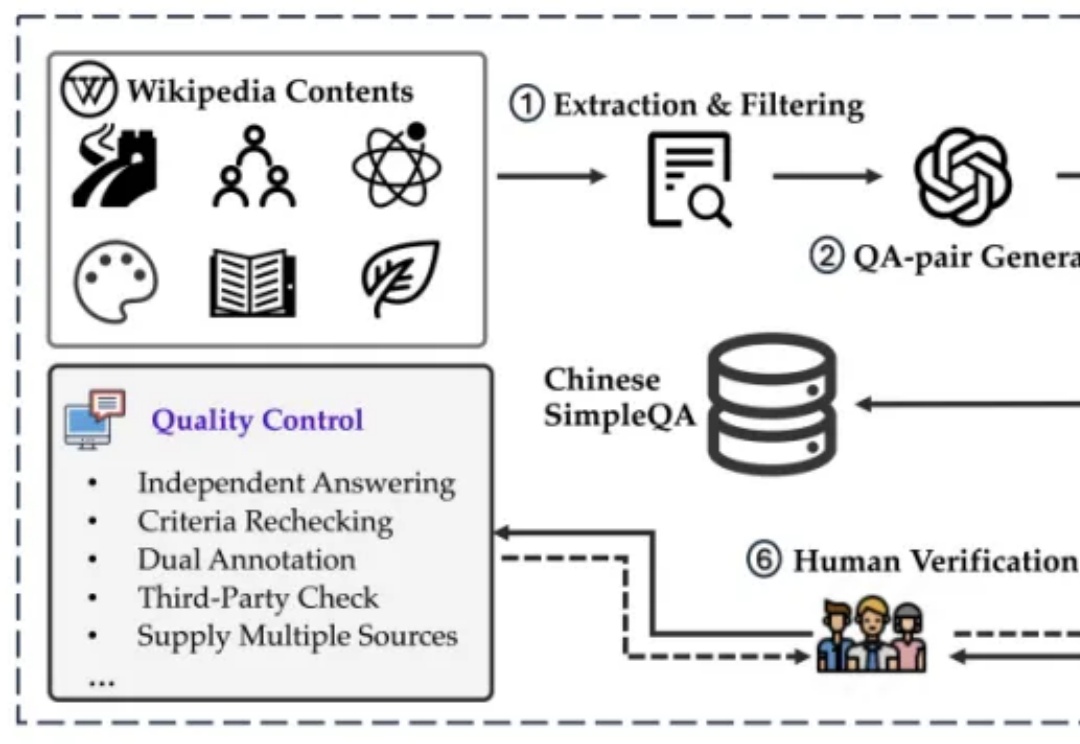
媲美OpenAI事实性基准,这个中文评测集让o1-preview刚刚及格如何解决模型生成幻觉一直是人工智能(AI)领域的一个悬而未解的问题。为了测量语言模型的事实正确性,近期 OpenAI 发布并开源了一个名为 SimpleQA 的评测集。而我们也同样一直在关注模型事实正确性这一领域,目前该领域存在数据过时、评测不准和覆盖不全等问题。例如现在大家广泛使用的知识评测集还是 CommonSenseQA、CMMLU 和 C-Eval 等选择题形式的评测集。
来自主题: AI技术研报
9996 点击 2024-11-20 15:02